DiÖ – Gesamt-SFB – Beitrag – Blog und Beitrag
Die ICLaVE 11 auf (virtuellem) Besuch in Wien. Einblicke in eine internationale Tagung mit 300 Teilnehmer*innen, 33 Sprachen und rund 200 Beiträgen.
Dieses Jahr sollte die 11th International Conference on Language Variation in Europe (lCLaVE |11) von 11. bis 14. April erstmals in Wien stattfinden. Alle hatten sich schon sehr auf ein Treffen mit Kolleg*innen gefreut, doch das Coronavirus machte auch dieses Jahr einen Strich durch die Rechnung, sodass die Konferenz wie viele andere komplett im virtuellen Raum stattfinden musste.
Das professionelle und hochmotivierte Organisationskomitee unter der Leitung von Alexandra N. Lenz (Universität Wien und Österreichische Akademie der Wissenschaften), das von einem ebenso professionellen und engagierten Technikteam unterstützt wurde, nahm diese Herausforderung gerne an und entwickelte sich in den letzten Wochen zu einem wahren Expert*innenpool für alle möglichen Funktionalitäten der technischen Tools und Abläufe.
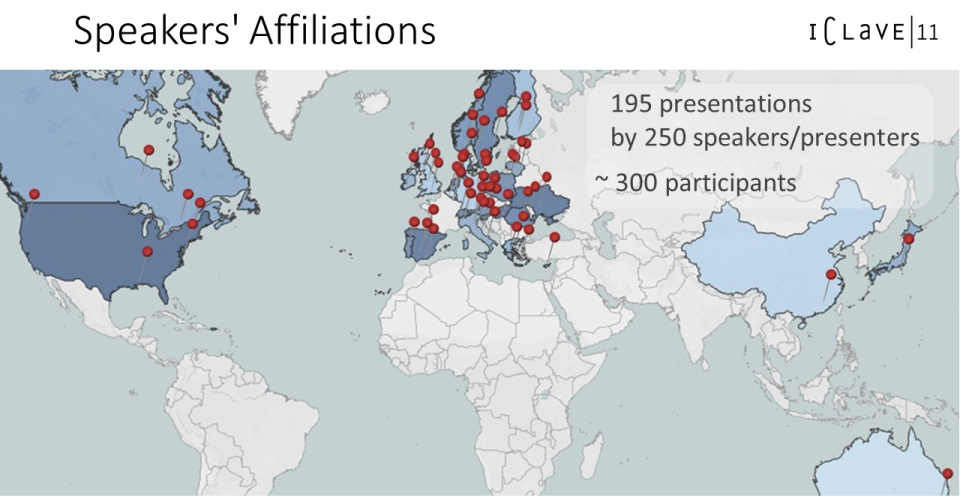
Das internationale Interesse an der insgesamt rund 300 Teilnehmer*innen umfassenden Konferenz war sehr groß: 31 Gutachter*innen wählten insgesamt 195 Präsentationen von rund 250 Sprecher*innen aus, sowie 22 Poster. Besonders erfreulich ist, dass trotz des Europa-Schwerpunktes der Tagung auch zahlreiche andere internationale Kolleg*innen aus Nordamerika, Asien und Australien mit dabei waren.
An vier Konferenztagen wurden in den Präsentationen insgesamt 33 Sprachen bzw. Varietäten aus 29 Ländern analysiert, die von Baskischer Variation auf Instagram, über griechische Varianten des Worts Corona bis hin zur Grammatik der Serbischen Gebärdensprache reichten.
Die gesamte Konferenz umfasste sowohl eher klassische als auch sehr innovative Themen und Methoden – vor allem Multi-Methoden-Ansätze erfreuten sich in vielen Projekten großer Beliebtheit. Dabei werden neben soziolinguistischen Interviews auch unterschiedliche kontrollierte Erhebungsmethoden angewandt, die von experimentalphonetischen Settings über Matched-Guise-Techniken bis zu Linguistic-Landscaping-Methoden reichen. Auch Korpusstudien aller Art, von georeferenzierten historischen Korpora bis zu YouTube-Kommentaren, waren zahlreich vertreten. Die Flexibilität und Kreativität aller Forschungsgruppen, auch in der Pandemie an Daten von hoher Qualität zu gelangen, ist tatsächlich bemerkenswert.
Da es uns unmöglich erscheint, den innovativen Inhalten der Konferenz mit einigen wenigen Worten und Absätzen zu den Inhalten der Vorträge, Poster und Multimediapräsentationen gerecht zu werden, haben wir selbst versucht, eine innovative Methode anzuwenden, um festzustellen, welche Themen bei der Konferenz am meisten vertreten waren. Mit Hilfe einer sogenannten „NLP-Topic-Modelling-Analyse“ haben wir insgesamt 181 Dokumente bestehend aus einzelnen Tagungstiteln und Tagungsabstracts mit Hilfe der Python-Bibliotheken Gensim und pyLDAvis bearbeitet und analysiert. Wir konnten damit untersuchen, nach welchen Themen (auch genannt „Topics“) sich die Beiträge zur ICLaVE|11 am besten gruppieren lassen und welche Ausdrücke am häufigsten vertreten sind. Da diese Art der Datenanalyse und -interpretation sehr umfangreich und aufwändig sein kann, haben wir uns entschlossen, hier fürs Erste nur die Themen bzw. Topics festzustellen. Zur Festlegung der Anzahl der Themen haben wir außerdem keinen „coherence score“, wie er für Topic-Modelling gängiger Weise empfohlen wird, berechnet. Stattdessen verlassen wir uns auf die visuelle Inspektion der Topics, welche sich möglichst wenig überlappen sollten.
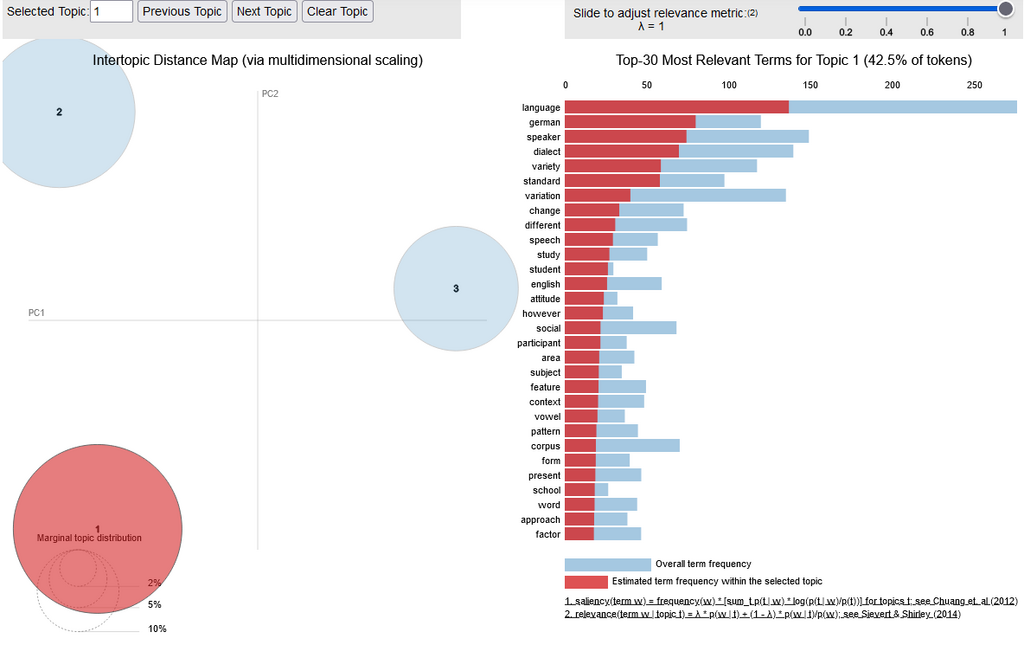
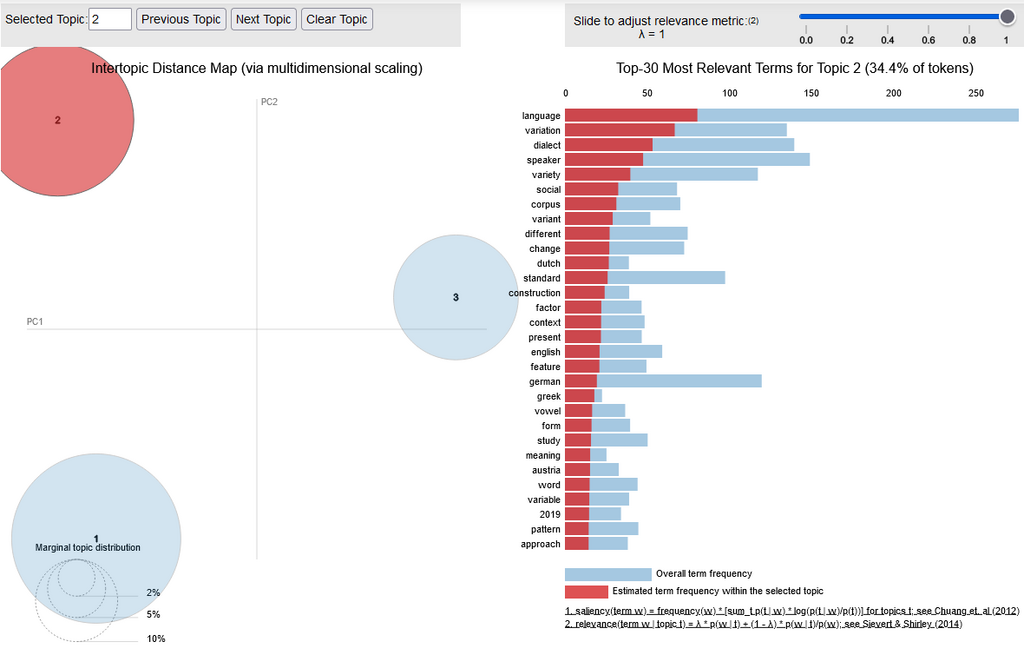
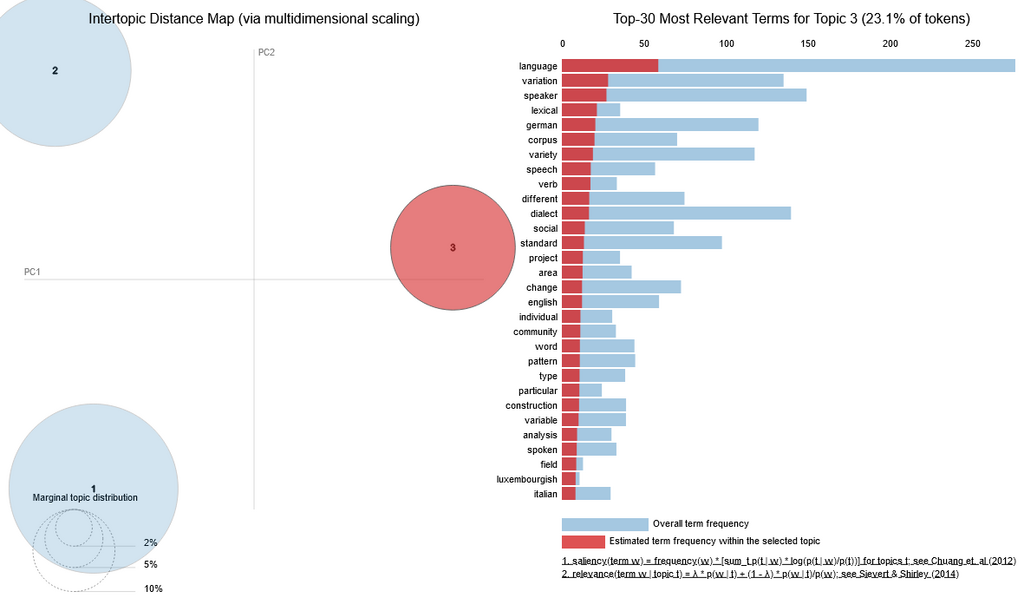
Auf den Grafiken sieht man auf der linken Seite die drei Hauptthemen als Kreise dargestellt, die sich durch die Anzahl der einzelnen Topics aus denen die Hauptkategorien zusammengesetzt sind, in größere (mehr Topics) und kleine (weniger Topics) Kreise unterteilt. Auf der rechten Seite sieht man die häufigsten bzw. relevantesten Begriffe innerhalb des jeweiligen Themas. Aufgrund der Internationalität der Konferenz war die Konferenzsprache Englisch und folglich auch die Tagungstitel und -beiträge, die unserer Analyse als Grundlage gedient haben. Deshalb finden sich in den Graphiken englische Begriffe. Für die Tagungstitel und -abstracts fanden wir mit dieser Methode somit die folgenden drei Hauptthemen:
Topic 1: Language variation among speakers of German (and English) dialect and standard varieties (Sprachvariation unter Sprecher*innen deutscher (und englischer) Dialekte und Standardvarietäten).
Das erste Thema „Sprachvariation unter Sprecher*innen deutscher (und englischer) Dialekte und Standardvarietäten“ dreht sich rund um Ausdrücke wie Deutsch, Sprecher*in, Dialekt, Standard, Varietäten und Wandel.
Topic 2: Dialect variation in different languages (Dialektvariation in verschiedenen Sprachen).
Das zweite Thema „Dialektvariation in verschiedenen Sprachen“ beinhaltete Ausdrücke wie Sprecher*in, Dialekt, Variation, Korpora, Varietät, Variante, Deutsch, Englisch, Niederländisch oder Griechisch.
Topic 3: Lexical variation in corpora of individual speakers and different social communities (Lexikalische Variation in Korpora individueller Sprecher*innen und verschiedene sozialer Gemeinschaften).
Das dritte Thema „Lexikalische Variation in Korpora individueller Sprecher*innen und verschiedene sozialer Gemeinschaften“ dreht sich um Schlagwörter wie Variation, Sprecher*innen, Lexik, Korpora und Varietäten.
Aber nicht nur über die vergangene Woche können wir Spannendes berichten, sondern wir möchten auch schon gerne einen Hinweis auf Zukünftiges geben. Denn bestimmt fragen sich viele bereits: Wo wird die nächste ICLaVE stattfinden? Wir freuen uns sehr, dass die ICLaVE 12 im Jahr 2024 erneut im schönen Wien stattfinden wird! Bis dahin bleiben wir zuversichtlich, dass wir spätestens dann alle Teilnehmer*innen physisch in Wien begrüßen dürfen und es mindestens genauso viele und noch mehr interessante und innovative Beiträge rund um die Themen Sprache und Variation geben wird. Bis dahin verbleiben wir in Vorfreude auf 2024 und sagen: Servus aus Wien!
Die ICLaVE 12 wird 2024 wieder in Wien stattfinden.
Referenzen
Asmussen, C.B., Møller, C. (2019). Smart literature review: a practical topic modelling approach to exploratory literature review. J Big Data6, 93 . https://doi.org/10.1186/s40537-019-0255-7
https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0255-7
Blei, D., A. Ng, and M. Jordan. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3:993–1022.
Ghanoum, T. (2022, January 1). Topic Modelling in Python with spaCy and Gensim. Medium. https://towardsdatascience.com/topic-modelling-in-python-with-spacy-and-gensim-dc8f7748bdbf
Griffiths, T.L. and Steyvers, M. (2004) Finding Scientific Topics. Proceedings of the National Academy of Sciences of the United States of America, 101, 5228-5235. https://doi.org/10.1073/pnas.0307752101
Owa, D. (2021) Identification of Topics from Scientific Papers through Topic Modeling. Open Journal of Applied Sciences, 11, 541-548. doi: 10.4236/ojapps.2021.104038. https://www.scirp.org/journal/paperinformation.aspx?paperid=108819
McLevey, John (2022). Doing Computational Social Science. A Practical Introduction. Los Angeles et al.: SAGE.


In: DiÖ-Online.
URL: https://www.dioe.at/artikel/3152
[Zugriff: 21.03.2026]